Краулинговый бюджет —
чтобы бот обходил приоритетные страницы, а не мусор
Навожу порядок в обходе: по логам видно, куда реально ходит Googlebot, что отдаёт 404/5xx и какие шаблоны съедают лимит. Дальше — robots.txt, параметры URL, ловушки фасетов и контроль в Search Console, с повторным срезом логов после правок.
Почему важные страницы долго не попадают в индекс?
1
Ловушки фасетов и «комбинаторный взрыв»
Фильтры, сортировки, календари и session id раздувают число URL. Бот крутится в шаблонах без ценности, пока продуктовые и контентные URL стоят в очереди.
2
Приоритетные URL почти не видят обхода
Новинки каталога, коммерческие посадочные и свежий контент ждут индексации: бюджет уходит на дубли, параметры и служебные пути.
3
Сигналы robots, canonical и noindex расходятся
Противоречивые директивы и карта сайта не совпадают с фактом на проде — краулер тратит время на разруливание вместо полезного обхода.
4
Решения принимают без логов
Только Search Console не покажет полную картину: не видно реальных кодов ответа, частоты ходов по мусорным цепочкам и доли обхода по шаблонам.
Что входит в оптимизацию краулинга
Навожу порядок в обходе: по логам видно, куда реально ходит Googlebot, что отдаёт 404/5xx и какие шаблоны съедают лимит. Дальше — robots.txt, параметры URL, ловушки фасетов и контроль в Search Console, с повторным срезом логов после правок.
Анализ серверных логов
Парсинг логов (Nginx, Apache, CDN), фильтрация поисковых ботов, топ URL по обходам, зоны 4xx/5xx и «пожиратели» бюджета. Сверка с приоритетными разделами сайта.
- Срез за согласованный период и типовые срезы после релиза
- Разрез по шаблонам URL и кодам ответа
- Выводы в виде очереди задач с приоритетом
Аудит robots.txt
Директивы Allow/Disallow, конфликты с картами сайта и важными путями, закрытие только мусора. Итог — конфиг без двусмысленностей для краулера.
- Согласование с фактическими URL на проде
- Проверка User-agent и краевых случаев
- Рекомендации по выкату и откату
Параметры URL и дубли
UTM, сортировки, фильтры: что индексировать, что канонизировать, что закрыть. Учёт настроек параметров в Search Console и внутренней перелинковки.
- Матрица: параметр → поведение → риск для трафика
- Минимизация дублей без потери полезных комбинаций
- Проверка после внедрения в GSC и логах
Crawl traps
Календари, бесконечные комбо фильтров, session id — выявление и отсечение правилами шаблона, редиректами и ограничениями генерации URL.
- Воспроизводимые примеры цепочек из логов
- Оценка влияния на индексацию приоритетов
- Критерии приёмки для разработки
Мониторинг в Search Console
Coverage, Crawl stats, запросы к важным шаблонам — до и после изменений. Связка с логами, чтобы не принимать решения только по отчёту.
- Контрольные метрики на период стабилизации
- Реакция на всплески ошибок и «Discovered — not indexed»
- Короткий отчёт для стейкхолдеров
ТЗ для разработки
Примеры URL до/после, правила редиректов, ограничения генерации ссылок в шаблонах — формат, который можно перенести в трекер.
- Зависимости между задачами
- Проверки на staging до прода
- План повторного среза логов
Инженерный подход к оптимизации краулинга
Не ставлю noindex «на глаз». Сначала логи и приоритеты разделов, затем согласованные правила в robots и шаблонах, снятие ловушек и проверка в Search Console плюс повторный срез логов после внедрения.
Логи — основа решений — Сбор и разбор серверных логов (при необходимости скрипты): куда ходит Googlebot, какие шаблоны URL забирают обход, какие коды ответа и цепочки повторяются.
Гигиена сигналов — Согласование robots.txt, canonical, noindex и параметров в Search Console с тем, что реально отдаёт сайт — без противоречий между «закрой» и «канонизируй».
Снятие ловушек — Фасеты, календари, session id — что раздувает комбинаторику, режем правилами, редиректами и логикой шаблонов так, чтобы не убрать полезные фильтры с трафиком.
Как проходит работа
Цикл от логов к чистому обходу: собираем данные, чистим, подтверждаем результат.
Шаг 1
Сбор логов и диагностика
Получаем серверные логи, фильтруем Googlebot, анализируем топ URI, выявляем зоны 404/500 и URL-потребители бюджета. Сверяем с приоритетными разделами из бизнеса. Результат: Отчёт о текущем поведении краулера: куда уходит бюджет, сколько теряется на мусоре, какие важные URL в простое.
Шаг 2
Аудит сигналов и правил
Анализируем robots.txt, canonical, noindex, hreflang, параметры в GSC. Находим конфликты, дублирующие директивы и несогласованность. Результат: Перечень несоответствий и список «серых зон», которые дезориентируют бота.
Шаг 3
Разработка плана очистки
Проектируем целевые правила: что закрыть, что канонизировать, какие ловушки убрать. Готовим ТЗ для разработчиков с примерами URL до/после. Результат: Приоритизированный план оптимизации с оценкой влияния на краулинговый бюджет.
Шаг 4
Внедрение и валидация
Контролируем применение правил на продакшене. Сразу после выката делаем повторный срез логов, отслеживаем метрики в GSC. Результат: Подтверждение, что бот перестал тонуть в мусоре и начал активнее обходить ценные страницы.
Примеры результатов
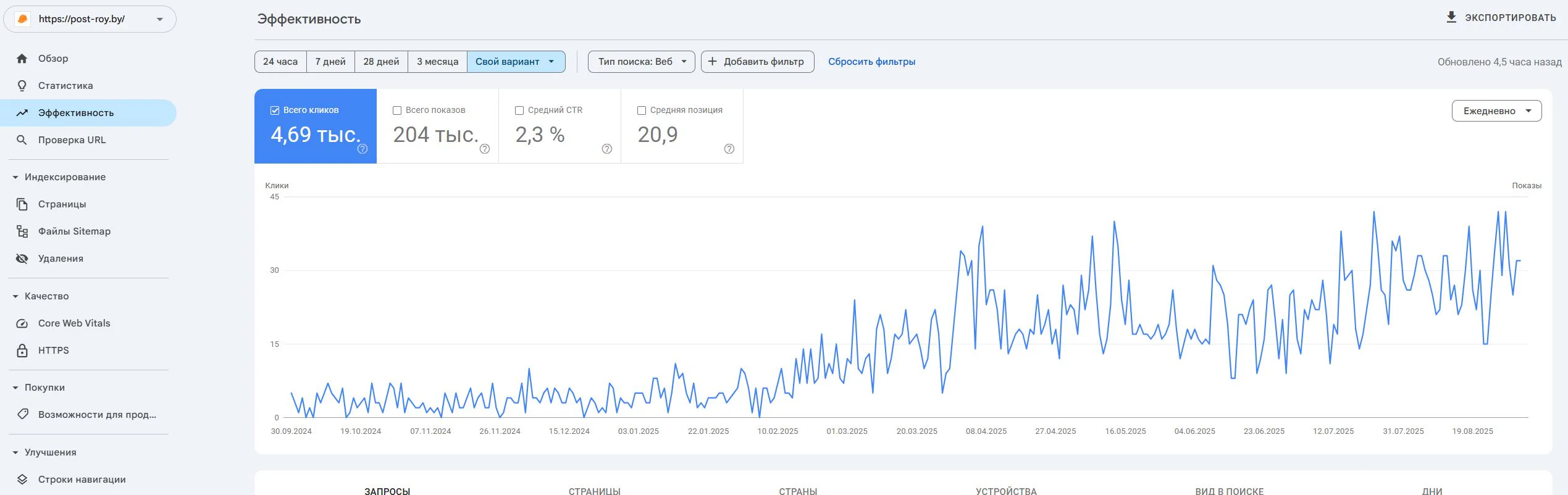
Post-Roy
Сайт по оказанию строительных услуг: промышленные полы и стяжка. Проект начался с нуля: без сайта, домена и цифровой репутации.
lengidroprom.ru
OpenCart-каталог насосного оборудования: переработка шаблонов, защита от ботов, Silo-структура, доверие и унификация 3000+ товарных карточек.
Лично
Эксперт, который ведёт проект
Не прячусь за отделом продаж: приоритеты, разборы и ответы по сути — от стратегии до отчётности.

SEO-стратег
Павел Борушко
Head of SEO @ Texode · Минск / гибрид
SEO-стратег с инженерным мышлением. Веду проекты от запуска с нуля до масштабирования высоконагруженных платформ: JS/SPA, поддомены, мультиязычность и мультирегиональность. Техаудит, стратегии индексации, семантика и структурированные данные — в зоне моей ответственности.
Часто задаваемые вопросы
Готовы навести порядок в краулинге?
Закажите аудит — я проанализирую логи и покажу, сколько бюджета теряется впустую.
Первая консультация бесплатно