Техническое SEO
Разбираю, что реально видит поисковик: что отдаёт сервер, как выглядит страница после скриптов, куда уходит обход по логам и насколько быстро грузятся важные шаблоны. На выходе — задачи для разработки с приоритетом и проверкой после релизов, а не отчёт ради галочки.
Почему список из сканера редко меняет позиции?
1
Отчёт сканера ≠ то, что видит Google
Десктопный краулер и мобильный Google с рендерингом часто расходятся. Если не сравнить HTML «как отдал сервер» и страницу после JS, важные блоки могут не попасть в индекс.
2
Обход тратится на мусорные URL
Фильтры, параметры, дубли и служебные шаблоны съедают лимит обхода, пока нужные страницы стоят в очереди. Без логов сложно доказать масштаб и сдвинуть приоритеты.
3
Скорость «зелёная в отчёте», тяжёлая у людей
Лаборатория и одна тестовая страница не отражают каталог, корзину и мобильную сеть. Поиск смотрит на реальный опыт; формальные зелёные галочки не заменяют проверку шаблонов.
4
Разработке скидывают простыню без порядка
Сотни строк без приоритета и критериев готовности: внедряют случайное, регрессии не ловят. Нужен бэклог тикетами — что делать первым и как проверить результат.
Что входит в работу
Разбираю, что реально видит поисковик: что отдаёт сервер, как выглядит страница после скриптов, куда уходит обход по логам и насколько быстро грузятся важные шаблоны. На выходе — задачи для разработки с приоритетом и проверкой после релизов, а не отчёт ради галочки.
Логи и краул-бюджет
Срез логов за согласованный период, фильтрация поисковых ботов, топ путей и «пожиратели» обхода. Сверка с индексацией и Crawl Stats в Search Console / Вебмастере.
- Кто сколько ходит и с какими кодами ответа
- Шаблоны URL, которые забирают львиную долю обхода
- Гипотезы с оценкой влияния на индексацию
Индексация и дубли
Canonical, noindex, пагинация, параметры, hreflang — на уровне шаблонов, а не «одной страницы». План сокращения дублей без потери полезных URL.
- Карта конфликтующих сигналов для типовых URL
- Что править конфигом, что — кодом
- Контроль после внедрения в GSC
JavaScript и SSR/SSG
Проверка рендеринга, гидратации и блокирующих ресурсов. Практичные рекомендации: что вынести в серверный HTML, где достаточно отложенной загрузки.
- Сравнение первого ответа и DOM после JS
- Риски для внутренних ссылок и мета-тегов
- Совместимость с вашим стеком (Next, SPA и т.д.)
Скорость и Core Web Vitals
LCP, INP, CLS на репрезентативных URL и устройствах: CDN, кэш, шрифты, сторонние скрипты. Упор на страницы, которые приносят деньги, а не только главную.
- Выборка URL под вашу структуру сайта
- Связка с шаблонами каталога и чекаута
- Повторная проверка после оптимизаций
Релизный контроль
Короткий чеклист перед выкладкой: robots, мета, коды ответа, риск регрессии по CWV. После релиза — мониторинг индексации в первые дни.
- Типовые ошибки при деплое фронта
- Кто смотрит GSC после релиза
- Критерии отката при критичной регрессии
Бэклог для разработки
Приоритизированные задачи: примеры URL, ожидаемое поведение, критерии приёмки — можно переносить в Jira/YouTrack без пересказа.
- Зависимости между задачами
- Оценка сложности «на пальцах» для планирования
- Связь с продуктовыми сроками релизов
Как строим работу: данные → гипотеза → задача → проверка
Свожу Search Console (и при необходимости Вебмастер), логи, обход с учётом JS, скорость и реальные шаблоны в одну картину. Каждая находка — это задача с ожидаемым эффектом, риском и очередью внедрения. После релиза — короткий контроль, чтобы регрессии не откатили улучшения.
Поведение бота как источник правды — Частота обходов, коды ответа, траектории по шаблонам URL — из логов и Crawl Stats. Так видно, куда реально уходит бюджет и что блокирует индексацию.
Рендеринг и индексация в паре — Проверка ключевых шаблонов на SSR/CSR/SSG: что в первом ответе сервера, что после исполнения скриптов, как ведут себя мета и внутренние ссылки.
Совместная работа с разработкой — Формулировки в терминах API, кэша, шаблонов и релизов; оценка сложности; что можно сделать конфигом, что требует кода. Без конфликта с продуктовыми сроками.
Как проходит работа
Три фазы — от снимка системы до устойчивых итераций с разработкой.
Шаг 1
Снимок
Сбор данных: GSC/Вебмастер, логи при доступности, краул с JS на ключевых шаблонах, базовый CWV. Карта узких мест и быстрых побед. Результат: Единая диагностика и список блокеров с приоритетом.
Шаг 2
План и внедрение
Формируем бэклог тикетов, согласуем спринты с dev, внедряем изменения конфигом и кодом. Контроль дублей и регрессий. Результат: Внедрённые правки с зафиксированными метриками «до».
Шаг 3
Итерации
Повторный срез логов и индексации, мониторинг CWV после релизов, корректировка гипотез. Фокус на устойчивом эффекте, а не на разовых всплесках. Результат: Нарастающая предсказуемость обхода и качества выдачи страниц.
Примеры результатов
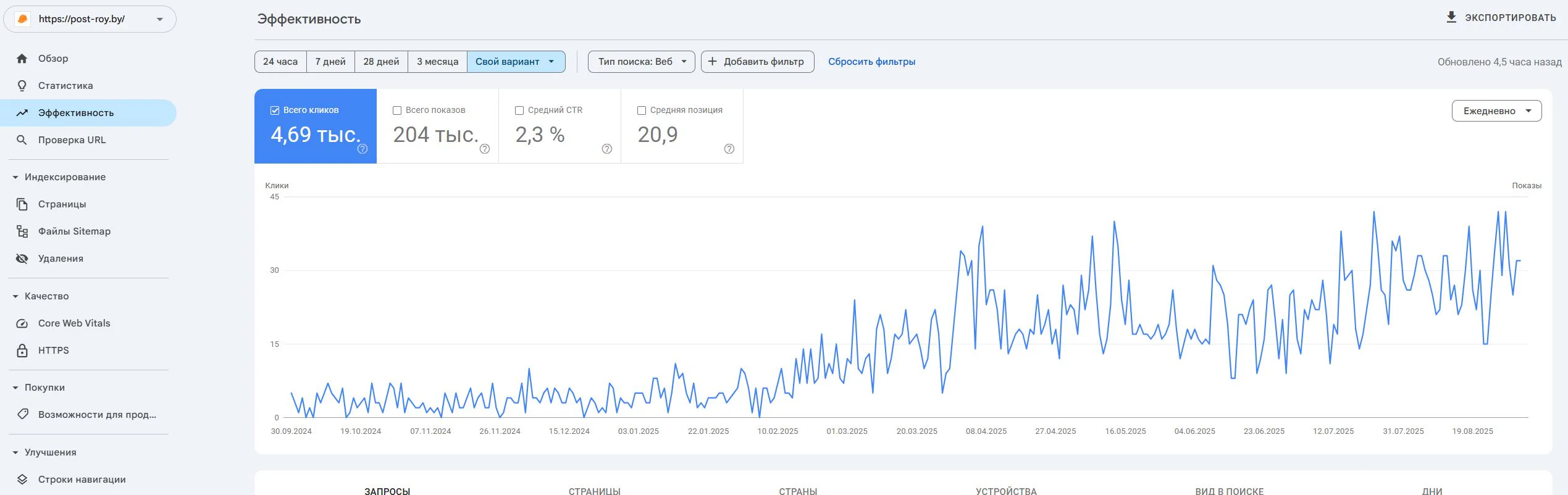
Post-Roy
Сайт по оказанию строительных услуг: промышленные полы и стяжка. Проект начался с нуля: без сайта, домена и цифровой репутации.
lengidroprom.ru
OpenCart-каталог насосного оборудования: переработка шаблонов, защита от ботов, Silo-структура, доверие и унификация 3000+ товарных карточек.
Лично
Эксперт, который ведёт проект
Не прячусь за отделом продаж: приоритеты, разборы и ответы по сути — от стратегии до отчётности.

SEO-стратег
Павел Борушко
Head of SEO @ Texode · Минск / гибрид
SEO-стратег с инженерным мышлением. Веду проекты от запуска с нуля до масштабирования высоконагруженных платформ: JS/SPA, поддомены, мультиязычность и мультирегиональность. Техаудит, стратегии индексации, семантика и структурированные данные — в зоне моей ответственности.
Часто задаваемые вопросы
Нужен устойчивый техничный фундамент?
Сделаем снимок и предложим первый спринт задач для разработки.
Первая консультация бесплатно