Python-автоматизация SEO
Пишем кастомные пайплайны на Python: парсинг выдачи, кластеризация десятков тысяч ключей, разбор логов, генерация мета и мониторинг с алертами. Встраиваем в ваши данные и процессы — экономим часы ручной работы.
SEO-задачи душат рутиной и не масштабируются?
1
Ручной сбор данных
Копирование выдач, экспорт из Ahrefs вручную, сводка позиций в Excel — это медленно и чревато ошибками.
2
Кластеризация вручную невозможна
Группировать 100k+ ключей без кода — потеря времени. Мягкая и жёсткая кластеризация требует алгоритмов.
3
Слепые зоны в индексации
Логи сервера хранят истину о поведении Googlebot, но без парсинга это просто сырые строки.
4
Массовая генерация мета-тегов
Для тысяч страниц нужны шаблоны Title/Description, которые не сломаются через месяц.
Что входит в Python SEO Automation
Пишем кастомные пайплайны на Python: парсинг выдачи, кластеризация десятков тысяч ключей, разбор логов, генерация мета и мониторинг с алертами. Встраиваем в ваши данные и процессы — экономим часы ручной работы.
Парсинг SERP и обогащение выдачи
Сбор топа, блоков SERP и PAA по большим спискам запросов — данные в удобном табличном виде.
- Playwright / Scrapy под антибот и динамическую вёрстку
- Нормализация HTML → структурированные поля для Pandas
- Ретраи, лимиты и учёт robots / политики источника
Кластеризация ключей
Жёсткая кластеризация по пересечению URL в топе и мягкая по тематике — большие объёмы за ночь.
- Hard / soft clustering и контроль качества кластеров
- Экспорт в формат для CMS или задач контента
- Параметры под вашу нишу и глубину выдачи
Анализ серверных логов
Nginx/Apache: частота обходов, ошибки, crawl waste — не сырые строки, а отчёт.
- Парсинг и агрегация по ботам, статусам и URL
- Сводки по разделам сайта и «прожорливым» шаблонам
- Выгрузка в Sheets или БД под дашборд
Генерация мета-тегов по шаблонам
Title и Description для тысяч URL с переменными из БД или экспорта CMS.
- Правила длины, стоп-слова и уникальность на уровне кластера
- Валидация и отчёт по конфликтам / дублям
- Формат импорта под вашу CMS или выгрузку в CSV
Мониторинг и оповещения
Регулярные проверки позиций, индексации, трафика — алерты в Slack / Telegram.
- Расписание и пороги срабатывания
- Снимок «до/после» в сообщении алерта
- Логирование прогонов для разбора инцидентов
Интеграция с вашим стеком
Выгрузка в Google Sheets, BigQuery, PostgreSQL, S3, внутренние API.
- Аутентификация и секреты вне репозитория
- Идемпотентные загрузки и инкрементальные обновления
- Схема полей согласована с аналитикой и SEO
ETL, очистка и контроль качества данных
Дедупликация, нормализация URL, слияние источников — чтобы downstream не ломался.
- Профилирование входных файлов и отчёт об аномалиях
- Единый справочник страниц / запросов на время пайплайна
- Тесты на выборке перед полным прогоном
Запуск, CI и передача команде
venv/poetry, README, пример `.env`, опционально GitHub Actions — чтобы запуск был повторяемым.
- Инструкция «как запустить локально и на сервере»
- Версионирование зависимостей и lock-файл
- Короткий онбординг для ваших разработчиков при необходимости
Инженерная автоматизация под вашу инфраструктуру
Не продаём «волшебный софт» — разрабатываем модули и пайплайны, которые встраиваются в текущий стек. Playwright, Pandas, Scrapy, БД и Google Sheets — под конкретные задачи и объёмы.
От задачи к коду — Сначала формулируем, что автоматизировать и зачем. Без кода ради кода — только полезные артефакты.
Масштабируемость — Скрипты держат 100k+ сущностей за приемлемое время и не падают при росте данных.
Прозрачность и воспроизводимость — Документация, логи, фиксированное окружение — не «чёрный ящик».
Интеграция с вашими системами — Результат уходит туда, где работаете: Sheets, БД, дашборды, S3, REST — как договоримся.
Как строится работа
От постановки задачи до скрипта, который стабильно отдаёт результат в вашу систему.
Шаг 1
Анализ и постановка
Фиксируем задачу, входные данные, желаемый выход и ограничения (объём, правовые рамки, SLA). Результат: ТЗ с примерами и критериями приёмки.
Шаг 2
Разработка
Пишем код на Python, подбираем библиотеки. Прогон на тестовых данных и промежуточные демо. Результат: Рабочий прототип, готовый к прогону на вашем объёме.
Шаг 3
Интеграция и передача
Запуск на ваших данных, cron / CI/CD, подключение экспорта. Документация и передача артефактов. Результат: Автоматизированный процесс, который можно использовать и поддерживать.
Шаг 4
Стабилизация и итерации
Наблюдение за первыми прогонами, правки по краевым случаям, договорённость о пост-поддержке. Результат: Скрипт устойчив к сбоям источников; понятно, как эскалировать поломки.
Примеры результатов
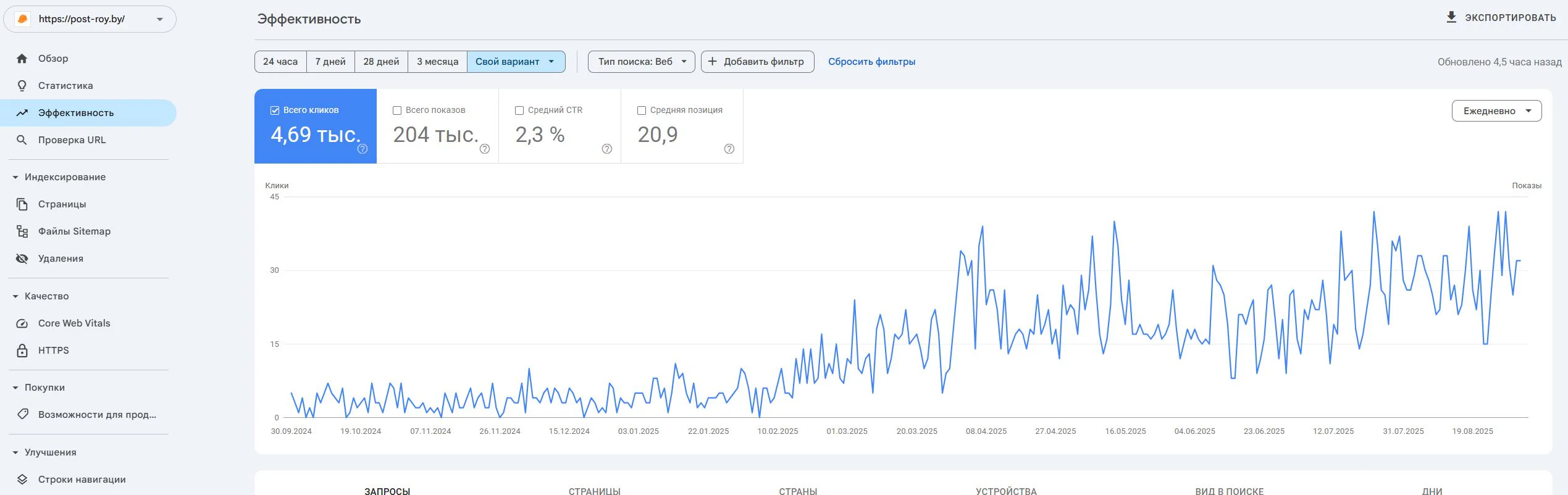
Post-Roy
Сайт по оказанию строительных услуг: промышленные полы и стяжка. Проект начался с нуля: без сайта, домена и цифровой репутации.
lengidroprom.ru
OpenCart-каталог насосного оборудования: переработка шаблонов, защита от ботов, Silo-структура, доверие и унификация 3000+ товарных карточек.
Лично
Эксперт, который ведёт проект
Не прячусь за отделом продаж: приоритеты, разборы и ответы по сути — от стратегии до отчётности.

SEO-стратег
Павел Борушко
Head of SEO @ Texode · Минск / гибрид
SEO-стратег с инженерным мышлением. Веду проекты от запуска с нуля до масштабирования высоконагруженных платформ: JS/SPA, поддомены, мультиязычность и мультирегиональность. Техаудит, стратегии индексации, семантика и структурированные данные — в зоне моей ответственности.
Часто спрашивают
Готовы выбросить рутину и получить работающие скрипты?
Обсудим задачу, формат данных и сроки — предложим архитектуру пайплайна.
Бесплатная первичная консультация