Технический SEO-аудит
Сопоставляю логи, сырой HTML и DOM после JS, профиль TTFB/LCP и политику URL. На выходе — приоритизированные тикеты с примерами URL, ожидаемым ответом сервера и критериями приёмки, чтобы команда могла взять в спринт без догадок.
Почему типовой технический аудит не объясняет просадку индексации?
1
Слепое пятно JS-рендеринга
Контент виден в браузере, но Googlebot получает пустой HTML. Для SPA или React это критично, а стандартные краулеры не показывают проблему.
2
Логи сервера игнорируются
Без Log File Analysis гипотезы строятся на догадках. Частота обходов, коды ответа, «пожиратели» краул-бюджета — только из логов.
3
Дубли и беспорядок в URL
Параметры, пагинация, сортировки плодят дубли, а каноники неверны. Краул-бюджет уходит в мусор.
4
Нет приоритетов для разработки
Список из 500 «ошибок» пугает команду, а эффект от внедрения непредсказуем.
Что входит в Технический SEO-аудит
Сопоставляю логи, сырой HTML и DOM после JS, профиль TTFB/LCP и политику URL. На выходе — приоритизированные тикеты с примерами URL, ожидаемым ответом сервера и критериями приёмки, чтобы команда могла взять в спринт без догадок.
Log File Analysis
Выгрузка за 30–90 дней, фильтрация Googlebot, разметка шаблонов URL; сверка с индексацией и Crawl Stats в GSC.
- Топ путей по hits и отличия от стратегии внутренних ссылок
- 4xx/5xx и всплески на мусорных параметрах
- Сопоставление частоты обхода с коммерческими шаблонами
JS Rendering Check
Ключевые шаблоны через headless и ручной разбор ответа: сырой HTML vs DOM, мета и ссылки до/после скриптов.
- SSR/SSG/CSR: где контент «появляется» слишком поздно
- Блокировщики и лишние зависимости в критическом пути
- Регрессии после релизов на контрольных URL
Crawl Budget Audit
Куда уходит бюджет: мусорные параметры, бесконечные комбинации, дубли; что закрыть noindex/robots или каноникалом.
- «Пожиратели» vs страницы без достаточного обхода
- Лимиты и приоритеты в sitemap vs фактический краул
- Связка с логами, а не только с краулером сайта
Speed Profiling
TTFB, LCP и цепочка ресурсов: Origin vs CDN, кэш, блокирующие скрипты и шрифты.
- Шаблоны с массово красными CWV в GSC
- Третьи стороны и тег‑менеджер на коммерции
- Критерии приёмки в цифрах по пилотным URL
Дубли и каноники
Параметры, пагинация, сортировки, зеркала; корректность canonical и самореференсов; конфликты hreflang при наличии.
- Дубли смысла vs дубли пути
- Правила для фасетов без потери полезных листингов
- Редиректы и склейка после смены структуры URL
Sitemap, robots и HTTP‑инварианты
Согласованность sitemap с индексируемым HTML, директивы robots, массовые коды ответа и «мягкие» ошибки.
- Рассинхрон sitemap и фактической выдачи
- Закрытие служебных путей без блока важных разделов
- Контрольные выборки статусов по шаблонам
HTTPS, заголовки и безопасная отдача
Редиректы HTTP→HTTPS, mixed content, базовые security‑заголовки и влияние на доверие и краул.
- Цепочки сертификатов и промежуточные редиректы
- HSTS и кэширование только после стабилизации схемы
- Зависимости CDN и порядок инвалидации
ТЗ для разработчиков
Примеры URL, ожидаемый статус и HTML, правила редиректов и каноникалов, зависимости задач и критерии приёмки.
- ICE или аналог для порядка внедрения
- Связка с релизным календарём и рисками отката
- Чеклист смоука после выката фикса
Инженерный разбор: от сырых данных к приоритетным задачам
Я не прогоняю сканер и не делаю выгрузку. Анализирую логи, сравниваю сырой HTML с DOM после JavaScript, профилирую TTFB/LCP. Итог — документ, который разработчики могут сразу брать в работу.
Данные из логов — не гипотезы — Анализ Nginx/Apache: частота обходов, топ путей, ошибки 4xx/5xx. Сверка с GSC — видим фактическое поведение Googlebot.
JS-рендеринг под микроскопом — Сравнение rendered vs raw HTML по шаблонам, поиск блокеров Googlebot при SSR/SSG/CSR. Фиксация кейсов, где контент появляется только после исполнения скриптов.
Дубли, каноники и краул-бюджет — Выявление дублей через параметры, пагинацию, сортировки. Корректность canonical и лимиты на индексацию.
ТЗ с приоритетами и критериями приёмки — Примеры URL, ожидаемый статус/HTML, правила редиректов, порядок внедрения с зависимостями. Никакого «списка рекомендаций».
Как строится аудит
Три шага от сырых данных до готового ТЗ для разработки.
Шаг 1
Логи
Получаем доступ к логам сервера за 30–90 дней, фильтруем запросы Googlebot. Размечаем шаблоны URL и сверяем с отчётами индексации GSC. Результат: Карта реальной индексации и краул-бюджета.
Шаг 2
Рендеринг
Проверяем ключевые шаблоны через headless-краулер с JS и вручную анализируем ответ сервера. Фиксируем случаи, где контент появляется только после выполнения скриптов. Результат: Список проблемных шаблонов с примерами URL.
Шаг 3
ТЗ
Формируем документ для разработчиков: конкретные URL, ожидаемый статус/HTML, правила canonical/редиректов, ограничения на параметры. Приоритеты и критерии приёмки. Результат: Приоритизированный список задач, готовый к спринту.
Примеры результатов
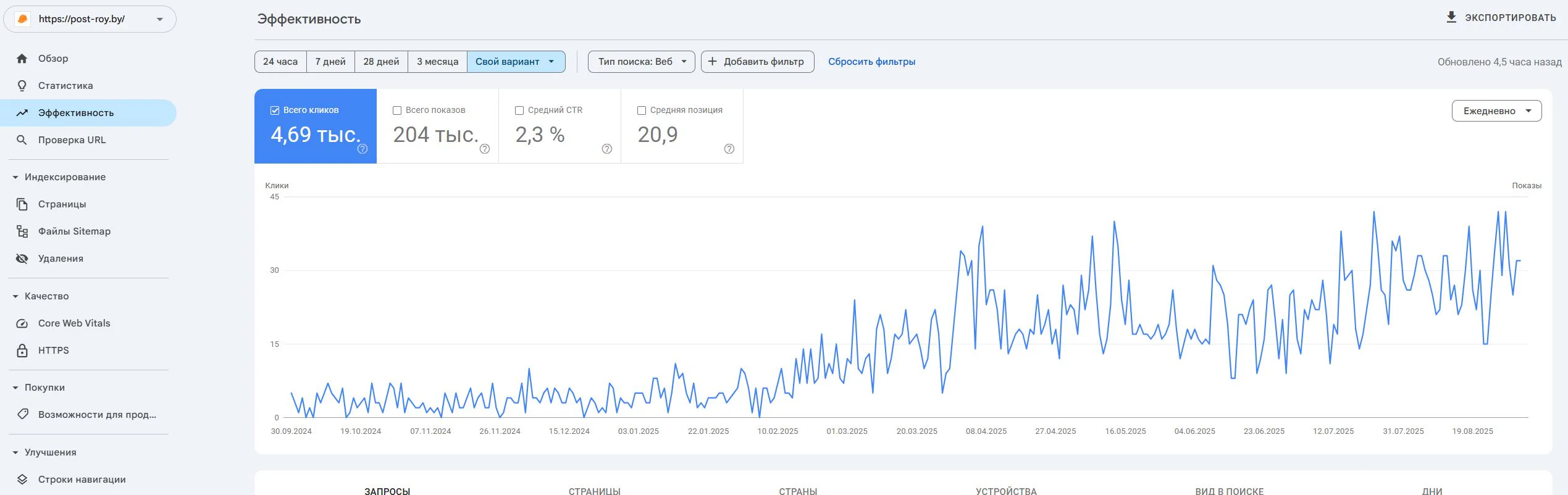
Post-Roy
Сайт по оказанию строительных услуг: промышленные полы и стяжка. Проект начался с нуля: без сайта, домена и цифровой репутации.
lengidroprom.ru
OpenCart-каталог насосного оборудования: переработка шаблонов, защита от ботов, Silo-структура, доверие и унификация 3000+ товарных карточек.
Лично
Эксперт, который ведёт проект
Не прячусь за отделом продаж: приоритеты, разборы и ответы по сути — от стратегии до отчётности.

SEO-стратег
Павел Борушко
Head of SEO @ Texode · Минск / гибрид
SEO-стратег с инженерным мышлением. Веду проекты от запуска с нуля до масштабирования высоконагруженных платформ: JS/SPA, поддомены, мультиязычность и мультирегиональность. Техаудит, стратегии индексации, семантика и структурированные данные — в зоне моей ответственности.
Частые вопросы
Готовы узнать, что на самом деле видит Googlebot на вашем сайте?
Технический аудит с логами и рендером — ТЗ для разработки вместо догадок об индексации.
Бесплатная первичная консультация