Semantic core
Page hierarchy and URL trees are derived from demand: corpus collection and normalization, hard/soft SERP clustering, merge/split rules, then template and content briefs. The deliverable is a release map — not a spreadsheet — plus guardrails against empty auto‑generated URLs.
Why does site structure drift from real demand and spawn duplicates?
1
Structure from a designer, not from queries
Sections and URLs are sketched without analyzing search demand. Pages miss user intent, traffic goes to competitors.
2
Cannibalization and duplicates
Multiple pages compete for the same query, or thin duplicates appear without unique value. Search engines split authority and can’t decide what to rank.
3
Uncontrolled auto‑generation of pages
The platform creates empty URLs or demand‑less pages — wasting crawl budget and diluting authority.
4
No clear content roadmap
Unclear which pages to build and in what order. Content is produced randomly, without priority alignment.
What’s included in semantic architecture
Page hierarchy and URL trees are derived from demand: corpus collection and normalization, hard/soft SERP clustering, merge/split rules, then template and content briefs. The deliverable is a release map — not a spreadsheet — plus guardrails against empty auto‑generated URLs.
Keyword corpus collection (100k+ keywords)
Exports, suggest mining, competitor parsing, normalization, deduplication. Methodology is documented so the corpus can grow without breaking clusters.
- Noise filters and intent tagging
- Industry‑specific normalization dictionaries
- Versioned exports to compare phases
Hard / soft clustering
Group by meaning and by real SERP overlap. One cluster = one primary URL; borderline cases tagged with explicit rules.
- SERP similarity thresholds plus manual review for edge cases
- Labels: merge / split / wait for GSC
- Mapping to existing production URLs
Silo & URL tree
Draft IA from pillars to leaves: folders, listing templates, pagination, rules against empty auto‑generation.
- CMS and template constraints baked in
- Rules for parameters and filters
- Cluster → page type matrix
Content briefs
For priority clusters: H1, H2–H3 outline, length, supporting phrases, references, interlinking.
- Release prioritization by ICE or traffic ceiling
- Shared tone of voice and fact checklist
- Editor acceptance template
Cannibalization protection
Cluster and URL intersections before build: merges, canonicals, block redistribution.
- Conflict table with recommended actions
- Rules for near‑duplicate commercial intents
- Checks after migrations or redesigns
Analytics & iterations
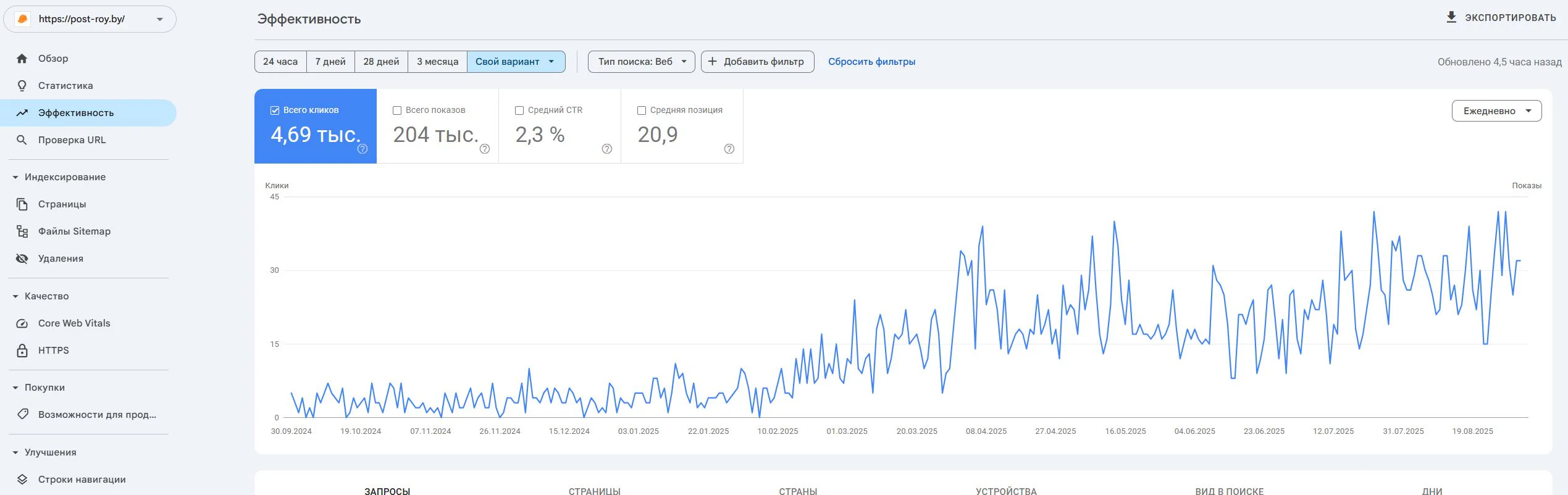
GSC: impressions, CTR, candidates to split or merge; priority refresh once data lands.
- Slices by template and folder
- Quarterly refinement backlog
- Handoff to technical SEO when SERP reality diverges from the plan
Engineering‑driven design from intent to content briefs
I don’t just collect keywords — I design the site scaffold around real demand. Parsing and clustering tens of thousands of queries, defining silo branches, locking URL structure, and delivering detailed content briefs for each cluster. This turns architecture into a multi‑month content roadmap, not a Figma diagram.
From demand to structure — Every section and URL is backed by data: search volume, intent, competitive landscape. No pages ‘just in case’.
Clustering before development — Hard/soft groups by meaning and SERP overlap. Conflicts and intersections are caught before coding, preventing internal URL wars.
Silo and thematic islands — From pillar topics to branches: folders, listing and detail templates, pagination rules. Silos and internal links lock in topical authority.
Content briefs as the final artifact — Every significant cluster gets: headlines, recommended length, secondary terms, competitor reference URLs, and interlinking instructions. Ready for writers.
How semantic architecture is built
Starting with pre‑designed URLs and then forcing keywords on top is far more expensive. The correct sequence is below.
Step 1
Parsing
Collect and clean keywords: deduplication, normalization, noise filters. Methodology is fixed to expand the corpus without breaking existing clusters. Outcome: A clean keyword corpus classified by intent.
Step 2
Clustering
Group by intent and SERP neighbors. Conflict zones tagged with explicit merge/split rules; some clusters deferred until GSC data arrives. Outcome: A cluster map — each cluster a candidate for one strong page.
Step 3
Structure
Draft URL tree, CMS alignment, design briefs for templates and content. Hard rules against auto‑generating demand‑less, content‑less pages. Outcome: A finalized URL architecture and a multi‑month content plan.
Personal
The expert who runs the work
No hiding behind a sales team: priorities, reviews, and straight answers—from strategy through reporting.

SEO Strategist
Pavel Barushka
Head of SEO @ Texode · Minsk / hybrid
SEO strategist with an engineering mindset. I lead projects from zero launch to scaling high-load platforms: JS/SPA, subdomains, multilingual and multiregional websites. Technical audits, indexation strategy, semantics and structured data are in my scope.
Frequently Asked Questions
Ready to build a site structure that grows with demand?
Order semantic architecture design — get a page plan that won’t be obsolete in a month.
Free initial consultation included