Technical SEO for complex sites —
crawl coverage, indexation, and speed — with your engineers
I focus on what search engines actually consume: the server HTML, the post‑JS page, bot logs and crawl paths, and speed on the templates that matter. The output is prioritized engineering work with acceptance checks after releases — not a checkbox PDF.
Why a scanner export rarely moves rankings
1
Your crawler report ≠ what Google sees
Desktop crawlers and mobile rendering-aware Googlebot often disagree. Without comparing raw server HTML vs the post‑JS DOM, important blocks may never enter the index.
2
Crawl budget burns on junk URLs
Filters, parameters, duplicates, and thin templates eat crawl while the URLs you care about wait in line. Logs make the waste visible and prioritization defensible.
3
Speed looks green in a lab — slow for real users
One lab URL doesn't represent catalog, checkout, and mobile networks. Search cares about real experience; green scores on a template aren't a substitute for template-level checks.
4
Engineering gets a wall of text with no order
Hundreds of lines without priority or acceptance criteria leads to random fixes and missed regressions. You need a ticket backlog — what ships first and how you verify it.
What's included
I focus on what search engines actually consume: the server HTML, the post‑JS page, bot logs and crawl paths, and speed on the templates that matter. The output is prioritized engineering work with acceptance checks after releases — not a checkbox PDF.
Logs & crawl budget
Log slices for an agreed window, search-bot filtering, top paths and crawl wasters. Cross-check with indexation coverage and Crawl Stats in Search Console / Webmaster.
- Who crawls how much and with which status codes
- URL templates that consume most crawl budget
- Hypotheses ranked by likely indexation impact
Indexation & duplicates
Canonical, noindex, pagination, parameters, hreflang at template level — not as one-off page fixes. A plan to reduce duplicates without losing valuable URLs.
- Map of conflicting signals for common URL types
- Config-only vs code changes
- Post-change verification in Search Console
JavaScript & SSR/SSG
Rendering, hydration, and render-blocking diagnostics. Practical guidance on server HTML for critical content vs deferred loading where it's safe.
- First response vs post-JS DOM comparison
- Risks for internal links and meta tags
- Fit to your stack (Next.js, SPA, etc.)
Speed & Core Web Vitals
LCP, INP, CLS on representative URLs/devices: CDN, cache, fonts, third-party scripts — focused on money pages, not only the homepage.
- URL sample aligned to your site structure
- Catalog and checkout templates where relevant
- Re-check after optimizations ship
Release guardrails
Short pre-ship checklist: robots, meta, status codes, CWV regression risk. Post-release indexation monitoring in the first days.
- Common front-end deploy pitfalls
- Who owns the GSC check after release
- Rollback criteria for critical regressions
Engineering backlog
Prioritized tasks: sample URLs, expected behavior, acceptance criteria — ready to paste into Jira/YouTrack without re-explaining.
- Dependencies between tickets
- T-shirt sizing for planning
- Alignment with product release trains
How we work: data → hypothesis → ticket → verify
I combine Search Console (and Webmaster when relevant), logs, JS-aware crawls, performance signals, and real templates into one view. Each finding becomes a task with expected impact, risk, and rollout order. After releases, a short control pass so regressions don't erase progress.
Bot behavior as the source of truth — Crawl frequency, status codes, URL-template paths — from logs and Crawl Stats. That shows where budget really goes and what blocks indexation.
Rendering and indexation together — Key templates on SSR/CSR/SSG: what's in the first server response vs after scripts, and how meta plus internal links behave.
Partnering with engineering — Specs in terms of APIs, cache, templates, and release trains; effort sizing; config-only vs code changes — aligned with product timelines.
How we work
Three phases — from a system snapshot to steady iterations with engineering.
Step 1
Snapshot
Pull GSC/Webmaster, logs when available, JS-aware crawls on key templates, baseline CWV. Map bottlenecks and quick wins. Outcome: Single diagnostic view and a prioritized blocker list.
Step 2
Plan & ship
Build a ticket backlog, align sprint cadence with dev, ship via config and code. Watch for duplicate and regression risks. Outcome: Shipped fixes with captured before metrics.
Step 3
Iterate
Re-sample logs and indexation, monitor CWV after releases, refine hypotheses. Focus on durable impact, not one-off spikes. Outcome: More predictable crawling and page quality in search.
Example results
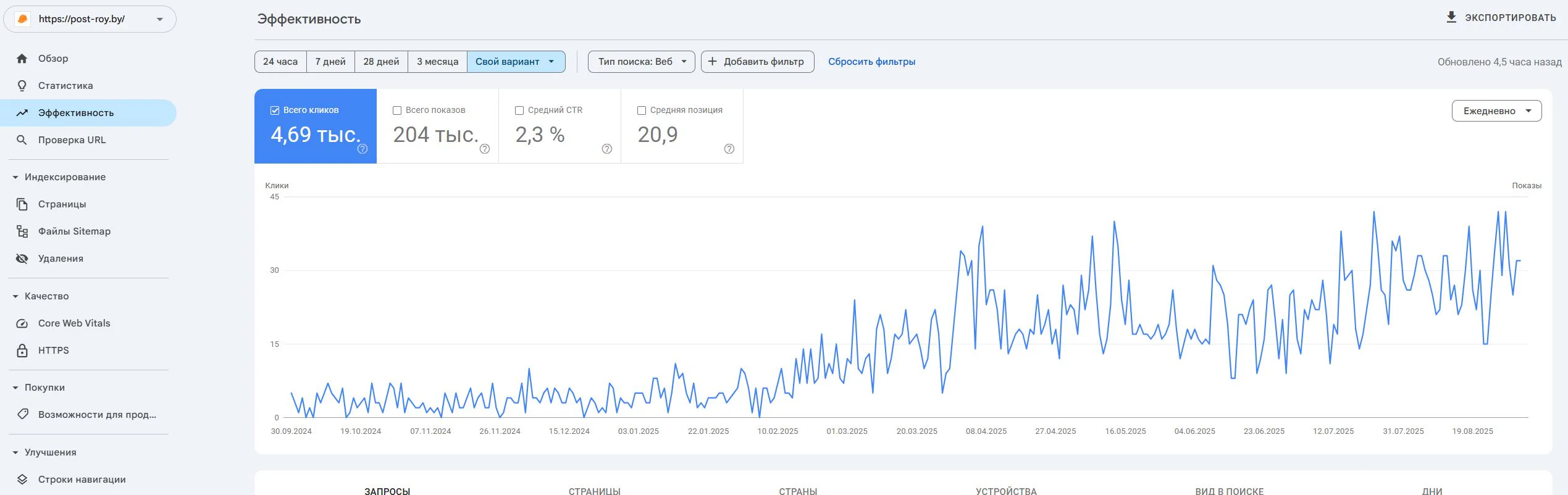
Post-Roy
A construction services website for industrial floors and screed. The project started from zero: no site, no domain, no digital reputation.
lengidroprom.ru
An OpenCart pumping equipment catalog: template redesign, bot filtering, silo architecture, trust factors and standardization of 3000+ product cards.
Personal
The expert who runs the work
No hiding behind a sales team: priorities, reviews, and straight answers—from strategy through reporting.

SEO Strategist
Pavel Barushka
Head of SEO @ Texode · Minsk / hybrid
SEO strategist with an engineering mindset. I lead projects from zero launch to scaling high-load platforms: JS/SPA, subdomains, multilingual and multiregional websites. Technical audits, indexation strategy, semantics and structured data are in my scope.
Frequently Asked Questions
Want a durable technical foundation?
Let's take a snapshot and propose the first engineering sprint.
Free initial consultation