Website content audit
Page quality, search intent, and cannibalization — clear actions per URL
URL inventory with GSC clicks and impressions, manual validation of disputed clusters, and a per‑page verdict — not generic advice. Merge, noindex, and strengthen plans align with internal linking and a roadmap so fixes do not create new chaos.
Why does index bloat and weak pages drag the whole domain down?
1
Thin and duplicated pages
After Google core updates, short, templated, and repetitive pages drag the entire domain down. Index bloat without real traffic.
2
Keyword cannibalization
Multiple URLs fight for the same keyword cluster — they all lose, and the right page can't solidify its top ranking.
3
Search intent mismatch
Commercial queries land on informational articles and vice versa. Users don't find what they seek, and Google drops your positions.
4
Gaps versus competitors
You're missing queries and formats where leaders capture traffic. Content planning relies on guesswork, not provable demand.
What's included
URL inventory with GSC clicks and impressions, manual validation of disputed clusters, and a per‑page verdict — not generic advice. Merge, noindex, and strengthen plans align with internal linking and a roadmap so fixes do not create new chaos.
Thin content & duplicate meaning
Short and templated pages, repeating blocks, practical duplicates: where to strengthen, 301/canonicalize, or noindex.
- Thin tied to clicks and impressions in GSC
- Template groups with mass risk
- Criteria for “expand” vs “merge”
Keyword cannibalization
Multiple URLs on one cluster: pick the leader, cut noise, or split commercial vs informational intent.
- Rank and URL alignment per cluster
- Internal linking plan after consolidation
- Control queries post‑implementation
Intent analysis
Page type vs real intent from SERP and behavior: what blocks to move, what structure to change.
- Commercial queries on informational URLs and vice versa
- Signals from top result formats
- Fix checklist without a full rewrite
Content gap
Queries and formats where leaders capture demand and you are weak or missing; priority by upside and effort.
- Topic map vs competitor landings
- Effort estimate for new pieces
- Gap tied to internal linking hubs
Internal linking & anchors
Where PageRank leaks, tunnels with no inlinks, over‑optimized anchors; aligned with cannibalization fixes.
- Hubs and spokes for commercial clusters
- Misleading anchor cleanup
- Coordination with dev on mass redirects
Titles, snippets & CTR
Title/H1/description fit vs query and competitor snippets; CTR uplift without clickbait.
- Duplicate titles and H1 conflicts
- Rich snippet loss risks when markup changes
- CTR hypotheses for top URLs
E‑E‑A‑T at URL level
Authorship, sources, policies, trust pages — mapped to specific URLs and blocks, especially in YMYL.
- Gaps in expert and contact signals
- Alignment with the actual product
- Minimum viable edits before release
Backlog & prioritization
Table with KIMK verdict, timelines, dependencies on dev and copy; done criteria and control metrics.
- ICE or impact‑first sequencing
- Writer briefs derived from the audit
- Re‑audit cadence at 6–12 months
How we bring order — inventory, diagnosis, plan
Without a unified URL table and a clear Keep / Improve / Merge / Kill decision, a report turns into a list of empty phrases. I give each page a reasoned verdict tied to GSC metrics, intent, and competitive landscape.
Thin & duplicate detection — Short pages, templated texts, repeating blocks, explicit duplicates. Practical duplicate content check: where a 301 / canonical is needed, and where unique content or merging into one strong URL is the answer.
Cannibalization & intent — Several documents cover the same cluster — remove the excess or split meanings (commercial vs informational). Decisions are tied to intent and internal linking, so new chaos doesn't appear.
Content Gap — Queries and formats where competitors rank and you have a weak or missing answer. Prioritized by potential and resources: what gives the maximum uplift for a reasonable amount of work.
E-E-A-T & quality — Google E‑E‑A‑T signals: authorship, sources, trust markup, 'About us' / expertise pages — especially in sensitive niches. Not a checklist for a PDF, but tied to specific URLs and on‑page elements.
Work process
Without a unified URL table and Keep / Improve / Merge / Kill decisions, a report quickly becomes a list of nice words with no execution.
Step 1
Inventory
Full list of pages with clicks/impressions from GSC, merged with CMS and crawler data if needed. Groups fixed: catalog, blog, landing pages, utility pages. Outcome: Unified inventory sheet of all URLs with basic metrics.
Step 2
Classification
Each page gets a status and reasoning: thin, duplicate, cluster conflict, intent failure. For edge cases — clear criteria so the team doesn't argue blindly. Outcome: Table with verdicts and priorities for every URL.
Step 3
Roadmap
Prioritized plan: what to tackle first by risk and traffic impact, what to postpone, which merges and noindex rules to align with development. Outcome: Actionable backlog split by urgency and impact.
Results examples
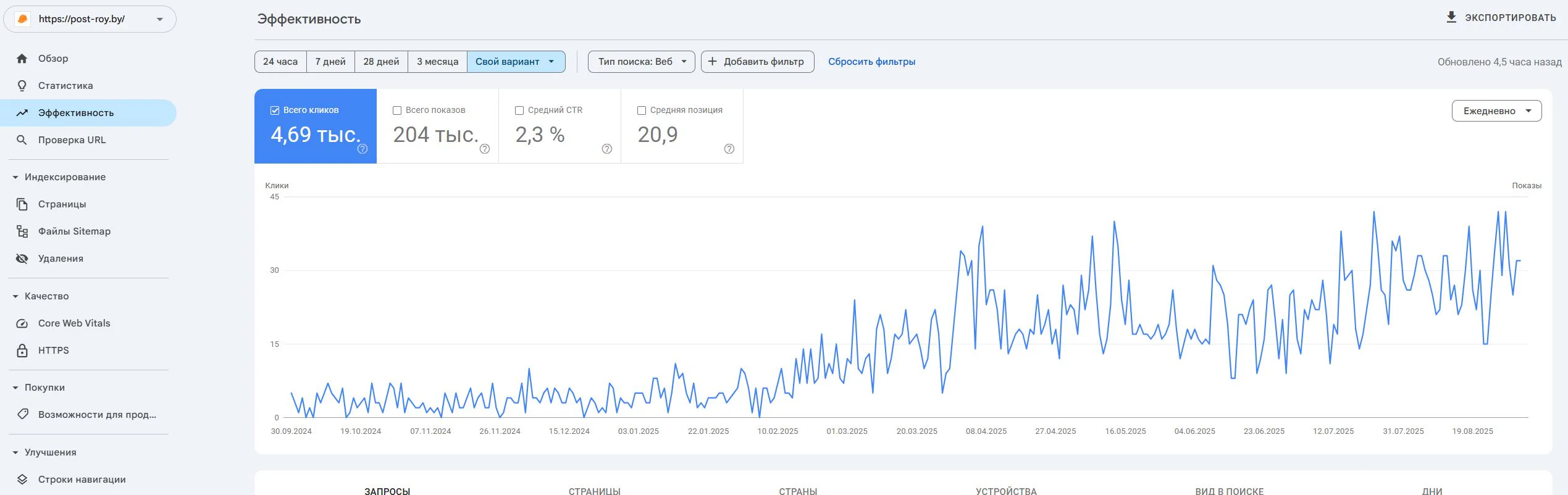
Post-Roy
A construction services website for industrial floors and screed. The project started from zero: no site, no domain, no digital reputation.
lengidroprom.ru
An OpenCart pumping equipment catalog: template redesign, bot filtering, silo architecture, trust factors and standardization of 3000+ product cards.
Personal
The expert who runs the work
No hiding behind a sales team: priorities, reviews, and straight answers—from strategy through reporting.

SEO Strategist
Pavel Barushka
Head of SEO @ Texode · Minsk / hybrid
SEO strategist with an engineering mindset. I lead projects from zero launch to scaling high-load platforms: JS/SPA, subdomains, multilingual and multiregional websites. Technical audits, indexation strategy, semantics and structured data are in my scope.
Frequently asked
Ready to clear content clutter?
Inventory, classification, and a roadmap — so content helps the domain instead of diluting it.
Including a free initial consultation