Full SEO audit
Consolidated GSC, JS rendering crawl, server logs, PageSpeed, and backlink exports — each finding manually validated against templates and revenue URLs. Deliverable: a task table with owners and dependencies, plus an executive summary.
Why standard audits don’t deliver results
1
Audits produce hundreds of unprioritized errors
Your team gets an 80+ page report with red flags, but nobody knows what to fix first. 80% of the findings are noise that doesn't affect traffic.
2
Tech, content, and backlinks are disconnected
Crawler data lives in one file, semantics in another, and backlinks in a third. There's no unified picture of how they interact and block each other.
3
Scanner-focused, not business-focused
'Red in Semrush' doesn't equal lost revenue. Scanners can't tell which pages make money and flood you with false positives.
4
No actionable plan for developers and writers
Tasks are vague: 'improve indexing', 'work on E-E-A-T'. Implementers need concrete tickets with impact estimates.
What’s included in a Full SEO Audit
Consolidated GSC, JS rendering crawl, server logs, PageSpeed, and backlink exports — each finding manually validated against templates and revenue URLs. Deliverable: a task table with owners and dependencies, plus an executive summary.
Technical audit
Crawl budget, canonicals, redirects, robots.txt, sitemaps, duplicates, HTTPS, URL patterns; for SPAs, compare post‑JS HTML with what search actually renders.
- Indexation and coverage on revenue templates
- Redirect chains and soft 404 patterns
- Parameters, facets, and pagination — where crawl budget leaks
Content & semantics
Keyword mapping, cannibalization, intent fit, E‑E‑A‑T signals; thin pages and duplicate meaning without added value.
- Query‑to‑URL map without H1/title conflicts
- Trust and commercial blocks on key landings
- Rules for mass listings and UGC sections
Backlink profile
Toxic donors, authority trends, anchors, competitive gaps; disavow only with clear risk and evidence.
- Spikes and drops dated against releases
- Manipulative pattern risks
- Priorities to earn links, not only prune
Core Web Vitals
LCP, INP, CLS from GSC field data; cluster URLs failing at scale and tie regressions to templates and third parties.
- Template‑level comparison, not just the homepage
- Post‑deploy regressions on a timeline
- Link to conversion on critical URLs
SERP & rich results
Visibility by query type, rich results (FAQ, HowTo, products), snippet stability; mismatches between SERP snippets and on‑URL content.
- Brand vs non‑brand and enriched result share
- Structured data validation on a sample set
- Risks of losing enhanced snippets after edits
IA & internal linking
Crawl depth to commercial clusters, hub‑and‑spoke, anchors and PageRank flow; nav conflicts and duplicate paths.
- Tunnels with no inlinks to important sections
- Pagination and breadcrumb spaghetti
- Aligning menu UX with the actual link graph
Prioritized action plan
Task table with ICE, owner (dev/content/marketing), and dependencies; done criteria and expected impact per workstream.
- Quick wins vs foundational changes
- Mapped to your release calendar
- Post‑implementation control metrics
Executive summary
Short memo: what caps growth, implementation order, resources and risks — without drowning leadership in crawler noise.
- Top five themes in business language
- Timeline estimate on the roadmap
- What can wait without traffic loss
An engineering audit grounded in real data
We don't auto-generate a PDF from a scanner. We pull data from GSC, server logs, a crawler, PageSpeed, and backlink tools. Every finding is manually validated, tied to traffic, and prioritized with ICE (impact/confidence/ease).
Single source of truth — Consolidate GSC, Screaming Frog (with JS rendering), server logs, PageSpeed API, backlink exports. Fix time periods and segments for apples-to-apples comparison.
Manual risk validation — Verify indexing of revenue pages, keyword cannibalization, link anomalies. Eliminate scanner noise that has no traffic impact.
ICE prioritization for every ticket — Each task gets scored: impact (on traffic/conversions), confidence, ease. The executor knows exactly what to do first.
How we work
Three stages: multi-source data collection, manual analysis of top risks, a prioritized report.
Step 1
Data collection
Connect GSC, run a JS-rendering crawler, request server logs, pull PageSpeed data, export backlinks. Fix time ranges and segments for clean comparison. Outcome: A five-source dataset ready for analysis.
Step 2
Analysis & validation
Manually inspect top risks: revenue-page indexability, commercial keyword cannibalization, link anomalies, CWV regressions. Filter out noise with zero traffic influence. Outcome: A confirmed list of issues tied to specific URLs and templates.
Step 3
Report & plan
Build a task table with ICE priority, assignee, and dependencies. Write an executive summary. Outcome: A document with concrete tickets and an implementation roadmap.
Example results
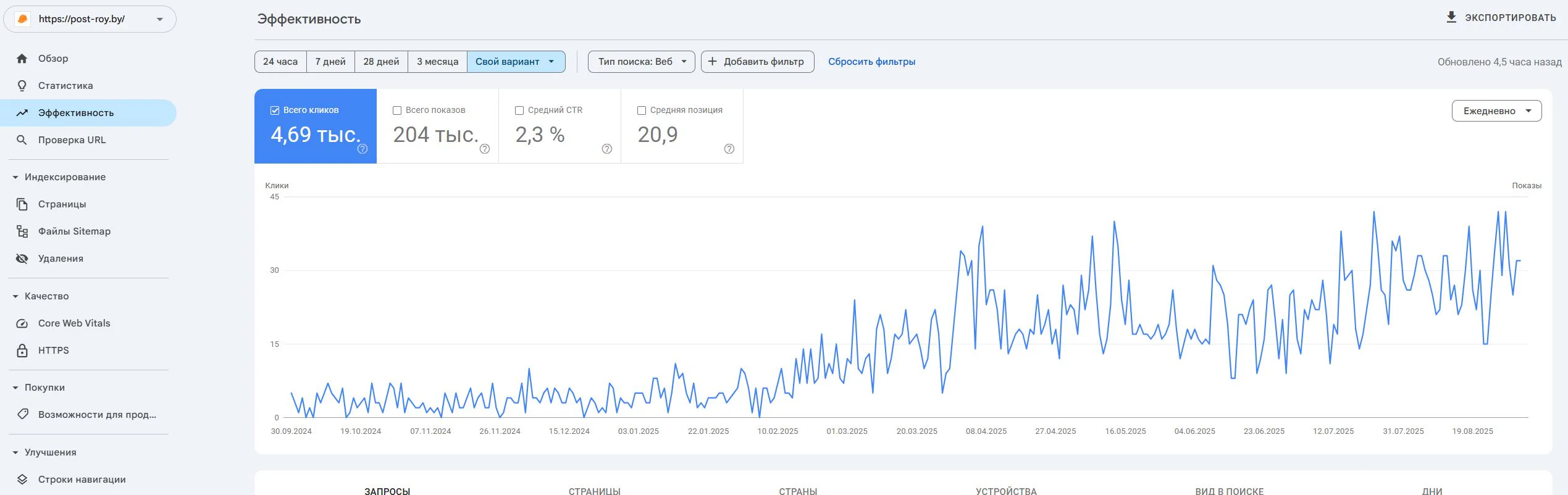
Post-Roy
A construction services website for industrial floors and screed. The project started from zero: no site, no domain, no digital reputation.
lengidroprom.ru
An OpenCart pumping equipment catalog: template redesign, bot filtering, silo architecture, trust factors and standardization of 3000+ product cards.
Personal
The expert who runs the work
No hiding behind a sales team: priorities, reviews, and straight answers—from strategy through reporting.

SEO Strategist
Pavel Barushka
Head of SEO @ Texode · Minsk / hybrid
SEO strategist with an engineering mindset. I lead projects from zero launch to scaling high-load platforms: JS/SPA, subdomains, multilingual and multiregional websites. Technical audits, indexation strategy, semantics and structured data are in my scope.
Frequently Asked Questions
Ready to discover what’s really holding your site back?
Full pass on consolidated data with manual validation — a prioritized ticket plan, not a scanner dump.
Free initial consultation