Python SEO automation —
scripts instead of routines
We build custom Python pipelines: SERP scraping, large-scale keyword clustering, log analysis, meta generation, and monitoring with alerts. Integrated with your data and workflows — fewer manual hours.
SEO chores are drowning you and don’t scale?
1
Manual data collection
Copy‑pasting SERPs, exporting from Ahrefs by hand, merging rankings in Excel — slow and error‑prone.
2
Clustering at scale is impossible manually
Grouping 100k+ keywords without code wastes days. Soft and hard clustering demand algorithms.
3
Blind spots in indexing
Server logs hold the truth about Googlebot behaviour, but without parsing they remain raw text.
4
Bulk meta‑tag generation
Thousands of pages need Title/Description templates that won’t break after the next update.
What’s included in Python SEO Automation
We build custom Python pipelines: SERP scraping, large-scale keyword clustering, log analysis, meta generation, and monitoring with alerts. Integrated with your data and workflows — fewer manual hours.
SERP scraping & SERP feature capture
Collect top results, SERP modules, and PAA across large query sets — structured for analysis.
- Playwright / Scrapy tuned for dynamic markup and basic anti-bot hygiene
- HTML → normalized fields ready for Pandas
- Retries, rate limits, and respect for robots / source policy
Keyword clustering
Hard clustering by SERP URL overlap and soft topical clustering — large volumes overnight.
- Hard/soft clustering with cluster-quality checks
- Exports formatted for CMS or content workflows
- Parameters tuned to your niche and SERP depth
Server log analysis
Nginx/Apache: crawl frequency, errors, crawl waste — reports, not raw lines.
- Parsing and aggregation by bot, status, and URL
- Section-level summaries and high‑churn templates
- Handoff to Sheets or a database for dashboards
Meta generation from templates
Title and Description for thousands of URLs with variables from DB or CMS exports.
- Length rules, stop words, and uniqueness at cluster level
- Validation with a conflict/duplicate report
- Import format tailored to your CMS or CSV workflow
Monitoring & alerts
Scheduled checks for rankings, indexing, traffic — Slack/Telegram notifications.
- Schedules and alert thresholds
- Before/after snapshots inside the alert payload
- Run logs for incident review
Stack integration
Google Sheets, BigQuery, PostgreSQL, S3, internal APIs.
- Auth and secrets kept out of the repo
- Idempotent loads and incremental updates where needed
- Field schemas aligned with analytics and SEO owners
ETL, cleanup, and data QA
Deduping, URL normalization, merging sources — so downstream doesn’t break.
- Input profiling with an anomaly report
- A unified page/query reference for the pipeline run
- Sample tests before full-volume execution
Runs, CI, and handover
venv/poetry, README, sample `.env`, optional GitHub Actions — reproducible execution.
- How to run locally and on a server
- Dependency versioning with a lockfile
- Short onboarding for your developers when needed
Engineering-driven automation for your stack
We don’t sell a «magic tool» — we ship modules and pipelines that fit your infrastructure. Playwright, Pandas, Scrapy, databases, and Google Sheets — scoped to real tasks and volumes.
Task first, code second — We define what to automate and why. No code for code’s sake — only useful artifacts.
Scalability — Scripts handle 100k+ entities within a reasonable time and stay stable as data grows.
Transparency & reproducibility — Documentation, logs, pinned environments — not a black box.
Integration with your systems — Outputs land where you work: Sheets, databases, dashboards, S3, REST — as agreed.
How the work is structured
From a clear problem statement to a script that reliably feeds your systems.
Step 1
Analysis & specification
We lock the task, inputs, desired outputs, and constraints (volume, legal guardrails, SLAs). Outcome: A brief with examples and acceptance criteria.
Step 2
Development
We write Python with the right libraries, test on samples, and share intermediate demos. Outcome: A working prototype ready for your real volume.
Step 3
Integration & handover
Runs on your data, cron/CI/CD wiring, export hooks. Documentation and artifact delivery. Outcome: An automated process you can operate and maintain.
Step 4
Stabilization & iterations
We watch early runs, fix edge cases, and agree how post-launch support works. Outcome: Resilience to source changes; a clear path to escalate breakages.
Sample results
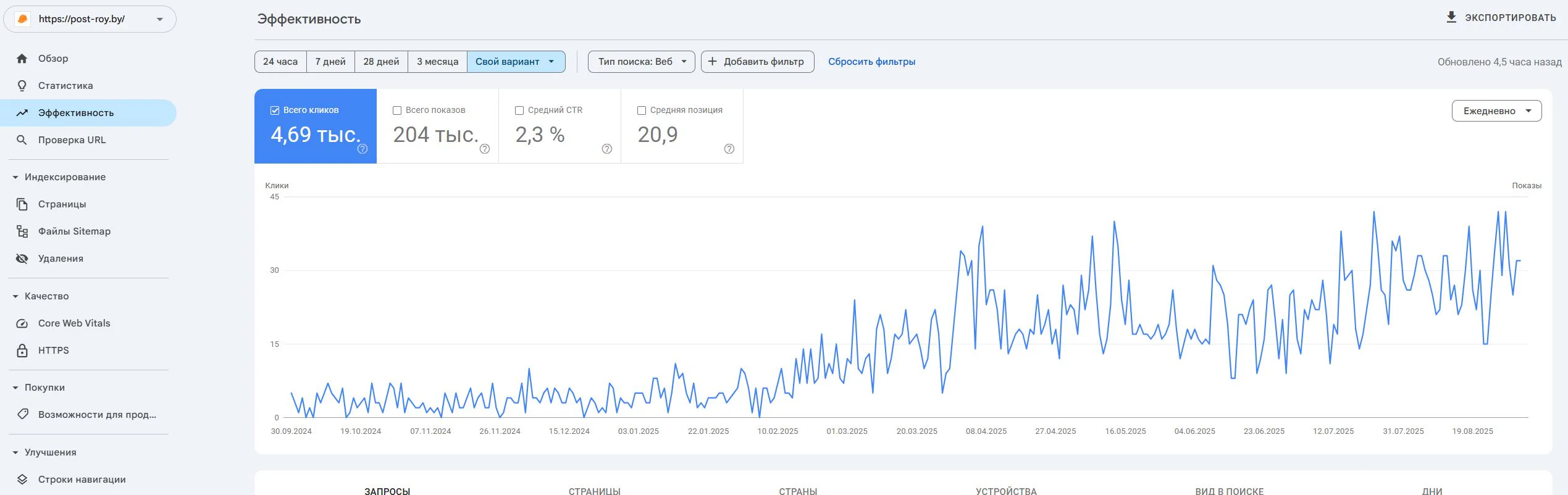
Post-Roy
A construction services website for industrial floors and screed. The project started from zero: no site, no domain, no digital reputation.
lengidroprom.ru
An OpenCart pumping equipment catalog: template redesign, bot filtering, silo architecture, trust factors and standardization of 3000+ product cards.
Personal
The expert who runs the work
No hiding behind a sales team: priorities, reviews, and straight answers—from strategy through reporting.

SEO Strategist
Pavel Barushka
Head of SEO @ Texode · Minsk / hybrid
SEO strategist with an engineering mindset. I lead projects from zero launch to scaling high-load platforms: JS/SPA, subdomains, multilingual and multiregional websites. Technical audits, indexation strategy, semantics and structured data are in my scope.
Frequently asked
Ready to ditch the rote work and get working scripts?
Discuss the task, data formats, and timeline — we’ll propose a pipeline architecture.
Free initial consultation included