Technical SEO audit —
logs, JS render, crawl budget, and speed — dev-ready specs, not a crawler dump
Cross‑reference server logs, raw HTML vs post‑JS DOM, TTFB/LCP profiling, and URL policy. Deliverable: prioritized tickets with example URLs, expected server responses, and acceptance criteria your team can schedule without guesswork.
Why don’t typical technical audits explain indexation drops?
1
JS rendering blind spot
Content is visible in the browser, but Googlebot receives empty HTML. Critical for SPAs or React — standard crawlers don’t show the issue.
2
Server logs are ignored
Without Log File Analysis, hypotheses are guesswork. Crawl frequency, status codes, crawl‑budget wasters — only from logs.
3
Duplicate content and messy URLs
Parameters, pagination, sorting create duplicates while canonicals are wrong. Crawl budget is wasted on garbage.
4
No development priorities
A 500‑error list scares the team, and the effect of fixing any single issue is unpredictable.
What’s included in a Technical SEO Audit
Cross‑reference server logs, raw HTML vs post‑JS DOM, TTFB/LCP profiling, and URL policy. Deliverable: prioritized tickets with example URLs, expected server responses, and acceptance criteria your team can schedule without guesswork.
Log File Analysis
30–90 day exports, Googlebot filtering, URL template tagging; cross‑check with indexation and Crawl Stats in GSC.
- Top paths by hits vs your internal linking strategy
- 4xx/5xx spikes on junk parameters
- Crawl frequency vs commercial templates
JS Rendering Check
Key templates via headless plus manual response review: raw HTML vs DOM, meta and links before/after scripts.
- SSR/SSG/CSR cases where content appears too late
- Blockers and heavy deps on the critical path
- Post‑release regressions on control URLs
Crawl Budget Audit
Where budget goes: junk parameters, infinite combinations, duplicates; what to noindex/robots or canonicalize.
- Wasters vs under‑crawled important clusters
- Sitemap priorities vs actual crawl
- Grounded in logs, not site‑crawler alone
Speed Profiling
TTFB, LCP chain: origin vs CDN, caching, blocking scripts and fonts.
- Templates with mass red CWV in GSC
- Third parties and tag managers on commerce paths
- Numeric acceptance targets on pilot URLs
Duplicates & Canonicals
Parameters, pagination, sorts, mirrors; canonical and self‑reference correctness; hreflang conflicts when present.
- Intent duplicates vs path duplicates
- Facet rules without killing useful listings
- Redirects and merges after URL structure changes
Sitemap, robots & HTTP invariants
Sitemap vs indexable HTML, robots directives, mass status codes and soft error patterns.
- Drift between sitemap and what’s actually served
- Closing utility paths without blocking key sections
- Status sampling by template
HTTPS, headers & safe delivery
HTTP→HTTPS redirects, mixed content, baseline security headers and crawl/trust impact.
- Cert chains and intermediate hops
- HSTS only after scheme is stable
- CDN dependencies and invalidation order
Developer‑ready technical assignment
Example URLs, expected status/HTML, redirect and canonical rules, task dependencies, acceptance criteria.
- ICE‑style ordering for implementation
- Mapped to release calendar and rollback risk
- Post‑fix launch smoke checklist
Engineering analysis: from raw data to prioritized tasks
I don’t run a scanner and dump a report. I analyze logs, compare raw HTML with DOM after JavaScript, profile TTFB/LCP. The output is a document developers can immediately act on.
Log data, not hypotheses — Nginx/Apache analysis: crawl frequency, top paths, 4xx/5xx errors. Cross‑checked with GSC — shows Googlebot’s actual behavior.
JS rendering under a microscope — Rendered vs raw HTML comparison by template; hunt for Googlebot blockers in SSR/SSG/CSR. Document cases where content only appears after script execution.
Duplicates, canonicals, crawl budget — Spot duplicate content through parameters, pagination, sorting. Correctness of canonical tags and indexation limits.
Prioritized tickets with acceptance criteria — Example URLs, expected status/HTML, redirect rules, implementation order with dependencies. No vague recommendation lists.
How the audit is conducted
Three steps from raw data to a dev‑ready specification.
Step 1
Logs
Obtain server log access for 30–90 days, filter Googlebot requests. Label URL templates and cross‑reference with GSC indexing reports. Outcome: A map of real indexation and crawl budget.
Step 2
Rendering
Check key templates through a headless crawler with JS and manually inspect server responses. Document cases where content only appears after script execution. Outcome: A list of problematic templates with example URLs.
Step 3
Technical Assignment
Produce a document for developers: specific URLs, expected status/HTML, canonical/redirect rules, parameter restrictions. Priorities and acceptance criteria. Outcome: A prioritized task list ready for the sprint.
Sample results
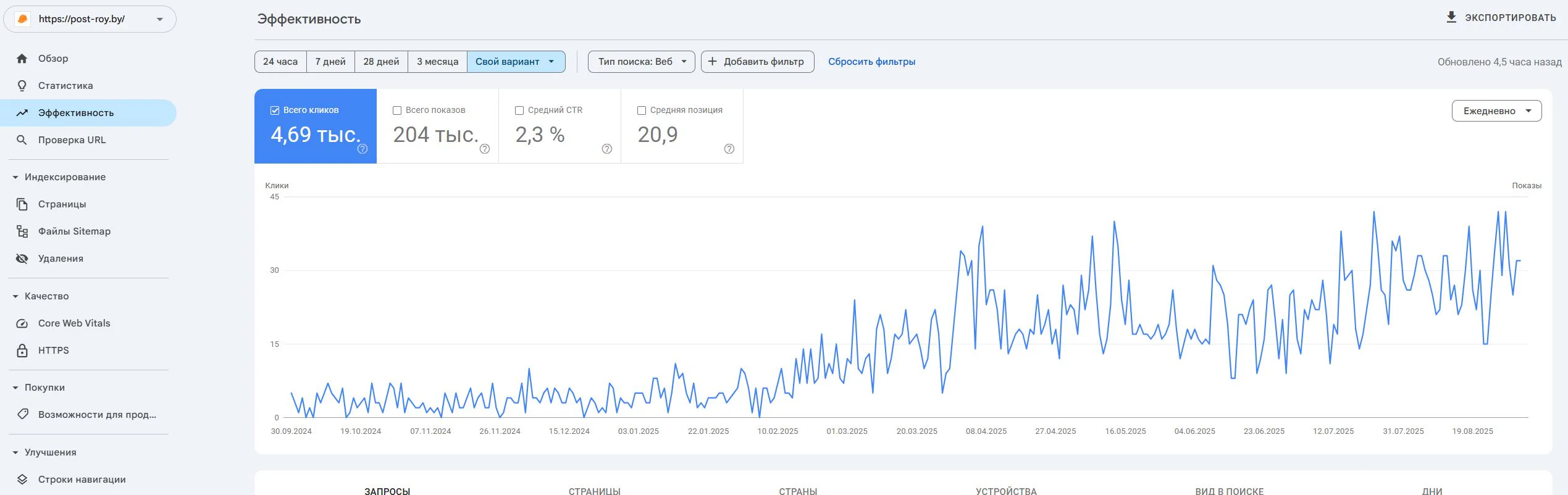
Post-Roy
A construction services website for industrial floors and screed. The project started from zero: no site, no domain, no digital reputation.
lengidroprom.ru
An OpenCart pumping equipment catalog: template redesign, bot filtering, silo architecture, trust factors and standardization of 3000+ product cards.
Personal
The expert who runs the work
No hiding behind a sales team: priorities, reviews, and straight answers—from strategy through reporting.

SEO Strategist
Pavel Barushka
Head of SEO @ Texode · Minsk / hybrid
SEO strategist with an engineering mindset. I lead projects from zero launch to scaling high-load platforms: JS/SPA, subdomains, multilingual and multiregional websites. Technical audits, indexation strategy, semantics and structured data are in my scope.
Frequently Asked Questions
Ready to see what Googlebot actually sees on your site?
Technical audit with logs and rendering — engineering specs instead of indexation guesswork.
Free initial consultation included